稀疏注意力(Sparse Attention)
基于注意力的深度学习模型例如Transformer,在捕捉输入序列中token之间的关系方面非常有效,即使距离较远。因此,它们被用于处理文本、图像和声音等输入,其中序列长度可以达到数千个token。然而,尽管注意力模块在捕捉长期依赖性方面十分有效,但在实际应用中,由于注意力计算的计算和内存需求随着序列长度n的增加呈二次增长(O(n^2)),对于长序列输入的应用受到了限制。
为了解决这个限制,DeepSpeed提供了一套稀疏注意力核心技术,通过块稀疏(block-sparse)计算,可以将注意力计算的计算和内存需求减少数个数量级。这套技术不仅减轻了注意力计算的内存瓶颈,还能高效地执行稀疏计算。其API允许与任何基于Transformer的模型进行方便集成。除了提供一系列稀疏结构外,它还可以处理任何用户定义的块稀疏结构。具体而言,稀疏注意力(Sparse Attention,SA)可以设计为在邻近的token之间计算局部注意力,或通过使用局部注意力计算的summary token来进行全局注意力。此外,稀疏注意力还可以允许随机注意力,或任何局部、全局和随机注意力的组合。因此,稀疏注意力将内存占用降低到O(wn)的水平,其中1 < w < n是一个参数,其值取决于注意力结构。
实现原理
这个库是基于PyTorch的,并通过Triton平台开发所需的核心功能;这些核心功能并不是用CUDA编写的,这为未来支持CPU/OpenCL/Vulkan留下了可能性。该库是DeepSpeed的扩展,可以通过DeepSpeed使用,也可以作为独立工具使用。DeepSpeed稀疏注意力核心处理的块稀疏计算分别在以下图中进行了展示,包括前向传播和反向传播。在这些图中,S代表块稀疏矩阵,D代表稠密矩阵。通过这些图例,可以看到DeepSpeed稀疏注意力核心如何处理块稀疏计算的前向传播和反向传播过程。
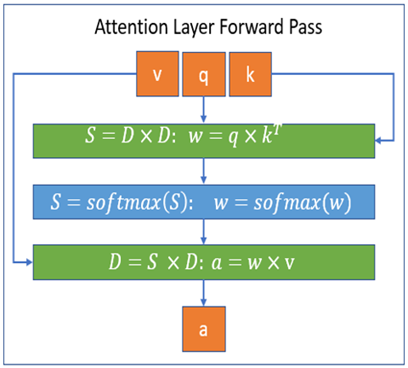
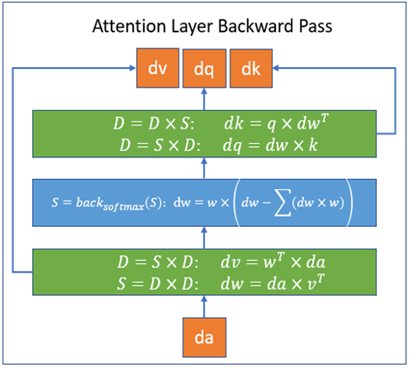
上图中,只有w是稀疏矩阵,注意力原本的q k v和a都是稠密矩阵,通过软件即可实现,不需要CUDA。
性能表现
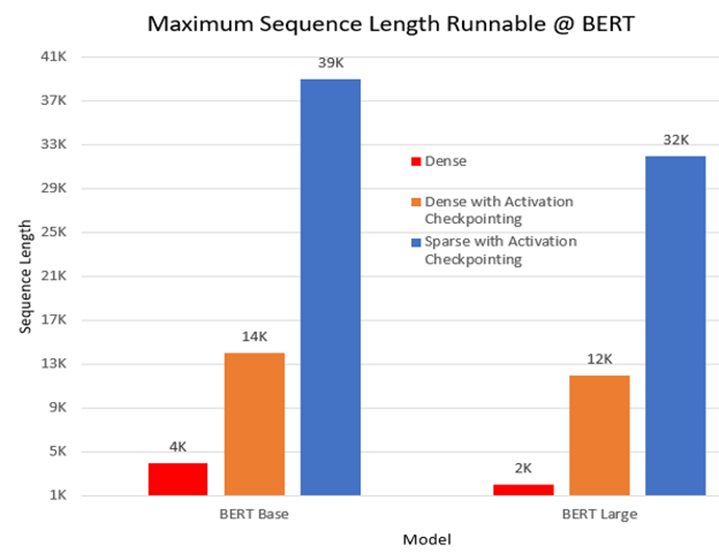
1) 最大序列长度。在一个预训练实验中,我们对BERT模型进行了三种设置的运行:稠密模式、带有Activation Checkpointing(重计算技术,部分层的计算结果不保存,当反向传播到这层时,重新前向计算这一层的激活值,再进行梯度更新,会增加一些训练时间,但是可以节省很多显存)的稠密模式以及带有Activation Checkpointing的稀疏注意力(SA)模式。与稠密模式相比,SA模式使得BERT base和large模型能够处理更长10倍和16倍的序列长度。下图展示了在BERT base和large模型中可运行的最长序列长度;该实验是在单个NVIDIA V100 GPU-32GB内存上,使用batch size为1进行的。图2所示为BERT base和large模型在不同设置下可以处理的最长序列长度。
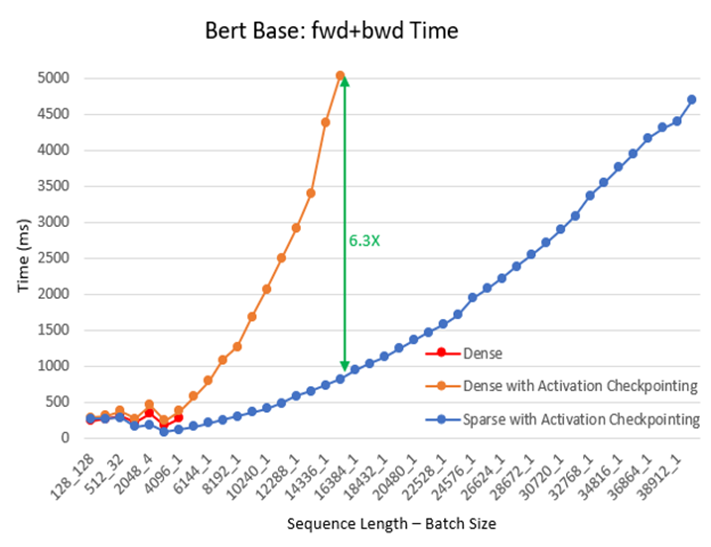
2) 训练速度。我们在不同的批量大小和序列长度下,持续进行了预训练实验,使用了BERT base/large和Megatron GPT2模型。在这个实验中,我们让训练继续进行100个迭代,并记录了最后30个迭代的平均时间。与稠密模式相比,SA减少了总体计算量,并提高了训练速度:随着序列长度的增加,提速效果更明显。对于BERT base模型,加速比高达6.3倍,如图3所示。
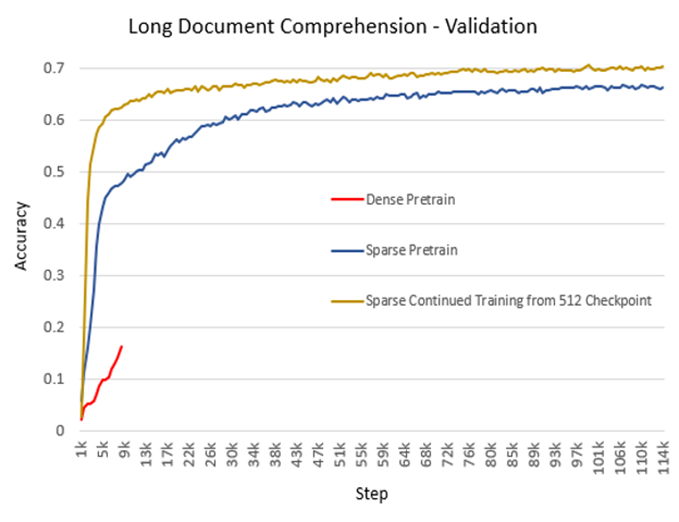
3)精度。与稀疏注意力(Sparse Transformer、Longformer、BigBird)相关的研究已经证明其在准确性方面与全注意力模型相当甚至更高。我们的实验结果也与之相吻合。除了更低的内存开销和更快的计算速度,在实际生产中,稀疏注意力在某些情况下可以达到更高的准确性和更快的收敛速度。图4展示了基于BERT进行长文档理解(2048序列长度)训练的生产模型的准确性。该实验分为三个设置:从头开始的稠密模式、从头开始的SA模式以及使用512序列长度的稠密模式从检查点继续训练的SA模式。结果表明,对于从头开始的预训练,相比于稠密模式,SA模式收敛更快且准确性更高。此外,SA模式在继续训练已经预训练的检查点时表现得更好,无论是在时间上还是准确性上。图4所示为在不同设置下进行训练的稠密模式和SA模式之间的精度比较。
代码示例
以微软的bing_bert 训练代码为例,
1、 编写sparse_attention配置文件,后面要传入get_sparse_attention_config函数
https://github.com/microsoft/DeepSpeedExamples/blob/master/training/bing_bert/deepspeed_bsz64k_lamb_config_seq128.json#L24-L33
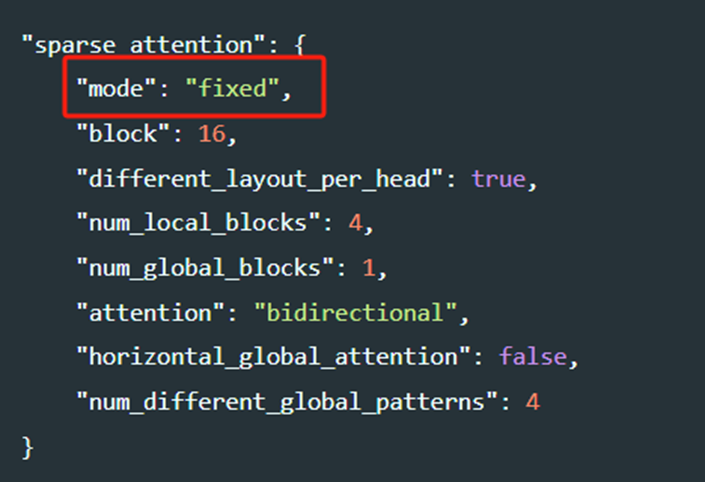
通过修改配置中的mode可以使用任何支持的稀疏结构更新 DeepSpeed 配置文件,并相应地设置参数,mode有多个实现,对应多种不同的SA结构:
SparsityConfig:这个模块是所有稀疏结构的父类,包含所有稀疏结构的共享特性,mode中没有这个选项,但包含它的参数。
见https://github.com/microsoft/DeepSpeed/blob/master/deepspeed/ops/sparse_attention/sparsity_config.py。
它接受以下参数:
- num_heads:确定层的注意力头数的整数。
- block:确定块大小的整数。当前的稀疏自注意力实现基于分块稀疏矩阵。该参数定义了这种方形块的大小;块 x 块。
- different_layout_per_head:确定是否应为每个注意力头分配不同的稀疏布局的布尔值,默认值为 false。
Fixed(FixedSparsityConfig):这个结构基于来自Generative Modeling with Sparse Transformers(https://arxiv.org/abs/1904.10509),其中局部和全局注意力由给定的参数固定:
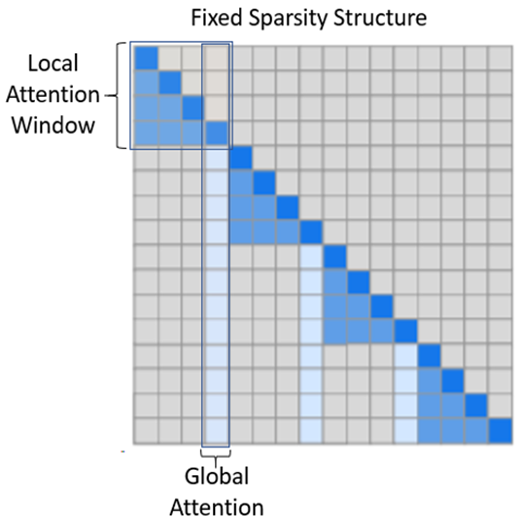
- num_local_blocks:确定局部注意力窗口中块的数量的整数。如图5所示(改编自原始论文),局部窗口中的标记会关注到与它们局部相邻的所有标记。对于自回归模型,如图所示,标记会关注到在局部窗口中它们之前出现的标记。对于像BERT这样的掩码模型,注意力是双向的。
-
- num_global_blocks:确定局部窗口中连续块的数量,用作全局注意力的代表;也在图5中有说明。
- attention:确定注意力类型的字符串。注意力可以是单向的,例如自回归模型,其中标记只关注上下文中出现在它们之前的标记。考虑到这一点,注意力矩阵的上三角部分为空,如图5所示。或者它可以是双向的,例如 BERT,其中标记可以关注它们之前或之后的任何其他标记。然后,注意力矩阵的上三角部分是图5中下三角的镜像。
- horizontal_global_attention:确定代表局部窗口的全局块是否也关注所有其他块的布尔值。这仅在注意力类型为双向时有效。从注意力矩阵的角度看,这意味着全局注意力不仅包括垂直块,还包括水平块。
- num_different_global_patterns:确定不同的全局注意力布局数量的整数。虽然全局注意力可以由哪个块/块代表任何局部窗口来固定,但由于有多个头,每个头可以使用不同的全局代表。例如,使用构建局部窗口的 4 个块和全局注意力大小为单个块,我们可以有 4 种不同的版本,其中每个局部窗口的第一个、第二个、第三个或第四个块可以成为该窗口的全局代表。此参数确定我们想要多少这样的模式。当然,基于 num_local_blocks 和 num_global_blocks,有一个限制。此外,如果将此设置为大于一,您需要将 different_layout_per_head 设置为 True。
- num_global_blocks:确定局部窗口中连续块的数量,用作全局注意力的代表;也在图5中有说明。
BSLongformer(BSLongformerSparsityConfig):这个结构是Longformer: The Long-Document Transformer(https://arxiv.org/abs/2004.05150)的修改后的版本,与单个token的稀疏性不同,我们提供了token块的稀疏性。定义此模式的参数包括:
- num_sliding_window_blocks:确定滑动本地注意力窗口中块的数量的整数。
- global_block_indices:一个整数列表,确定哪些块被视为全局注意力。给定的索引确定了所有其他token块关注的块,它们也关注所有其他token块。请注意,如果设置了 global_block_end_indices 参数,该参数将用作每个全局窗口的起始索引。
- global_block_end_indices:一个整数列表,确定全局窗口块的结束索引。默认情况下不使用此参数。但如果设置了它,它必须具有与 global_block_indices 参数相同的大小,并结合这两个参数,对于每个索引i,从global_block_indices[i]到global_block_end_indices[i](不包括)的块被视为全局注意力块。
BigBird(BigBirdSparsityConfig):这个结构基于 Big Bird: Transformers for Longer Sequences(https://arxiv.org/pdf/2007.14062 )。它以某种方式结合了固定、Longformer模式以及随机注意力的思想。以下参数定义了这个结构:
- num_random_blocks:确定每个行块中有多少个块会随机被选中的整数。
- num_sliding_window_blocks:确定滑动本地注意力窗口中块的数量的整数。
- num_global_blocks:确定有多少连续的块,从索引0开始,被视为全局注意力。全局块标记将被所有其他token块关注,并且它们也将关注所有token块标记。
Variable(VariableSparsityConfig):这个结构也结合了局部、全局和随机注意力的思想。此外,它具有定义可变大小局部窗口的灵活性。以下是定义这个结构的参数列表:
- num_random_blocks:一个整数,确定每个行块中有多少块会随机被选择。
- local_window_blocks:一个整数列表,确定每个局部注意力窗口中的块数量。它假设第一个数字确定了第一个局部窗口中的块数,第二个数字确定了第二个窗口中的块数,依此类推,最后一个数字确定了剩余局部窗口中的块数。
- global_block_indices:一个整数列表,确定哪些块被视为全局注意力。给定的索引确定了所有其他token块将关注的块,它们也会关注所有其他token块。请注意,如果设置了 global_block_end_indices 参数,该参数将用作每个全局窗口的起始索引。
- global_block_end_indices:一个整数列表,确定全局窗口块的结束索引。默认情况下不使用此参数。但如果设置了它,它必须具有与 global_block_indices 参数相同的大小,并结合这两个参数,对于每个索引i,从 global_block_indices[i] 到 global_block_end_indices[i](不包括)的块将被视为全局注意力块。
- attention:一个字符串,确定注意力类型。注意力可以是单向的,例如自回归模型,其中标记只关注上下文中出现在它们之前的标记。考虑到这一点,注意力矩阵的上三角部分为空,如上图所示。或者它可以是双向的,例如 BERT,其中标记可以关注它们之前或之后的任何其他标记。然后,注意力矩阵的上三角部分是图5中下三角的镜像。
- horizontal_global_attention:一个布尔值,确定代表局部窗口的全局块是否也会关注所有其他块。这仅在注意力类型为双向时有效。从注意力矩阵的角度看,这意味着全局注意力不仅包括垂直块,还包括水平块。
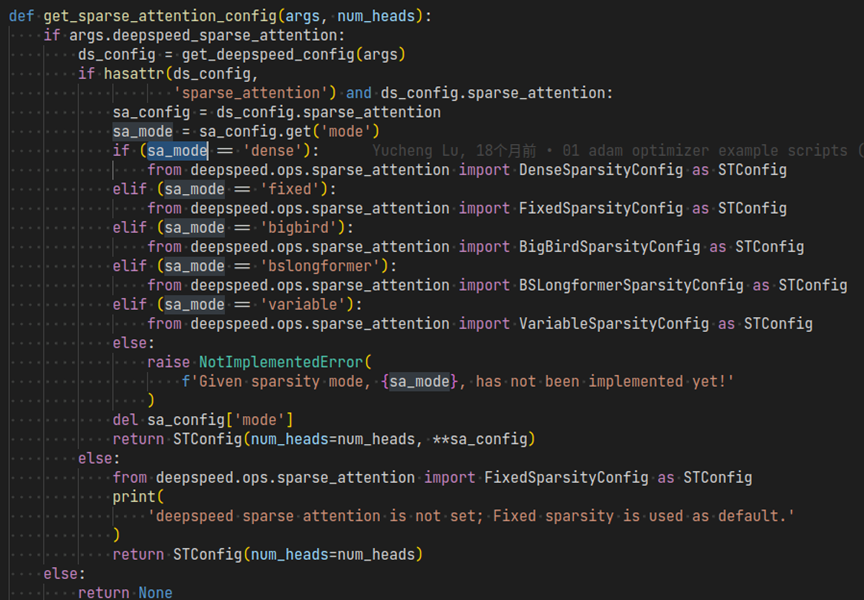
上述mode的配置具体加载到代码中后的示例:
2、 将上一步的稀疏注意力配置通过get_sparse_attention_config函数读取,传入模型初始化
class BertModel(BertPreTrainedModel):

3、encoder模型初始化时的注意力层更新为稀疏注意力
class BertEncoder(nn.Module):

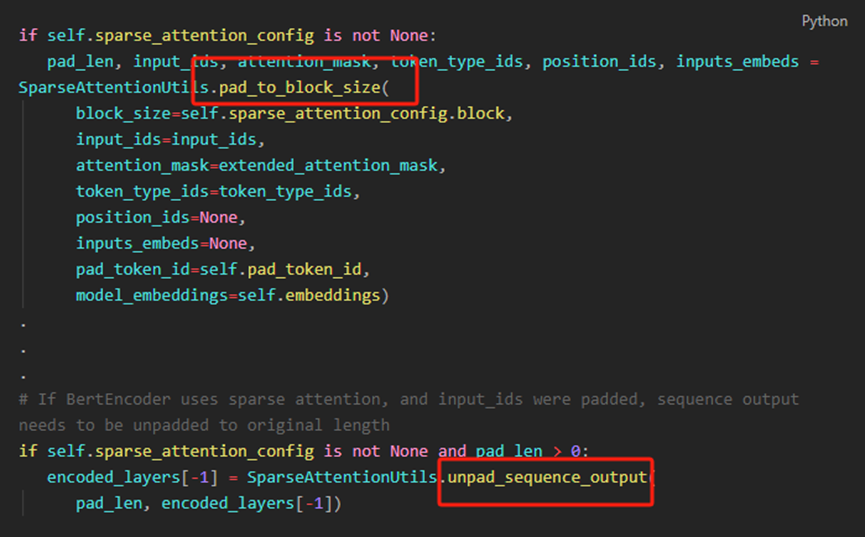
4、 输入数据pad和unpad
您可能需要对input_ids和attention_mask的序列维度进行填充,使其成为稀疏块大小的倍数,用在模型forward里
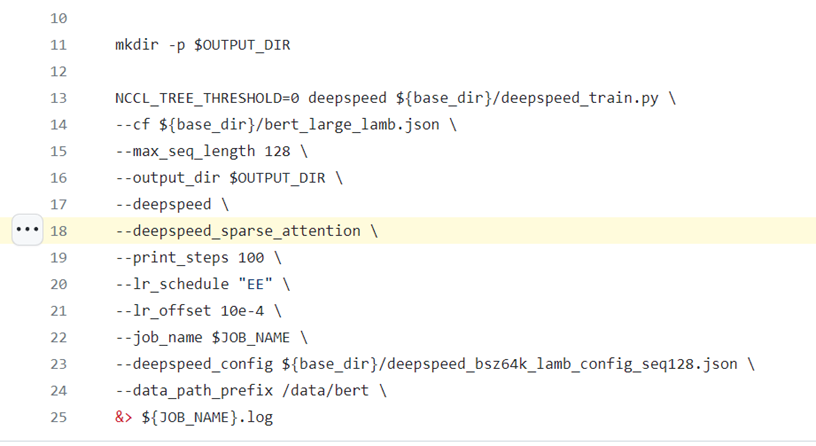
要使用DeepSpeed Sparse Attention,需要在启动脚本中通过--deepspeed_sparse_attention参数启用它,见https://github.com/microsoft/DeepSpeedExamples/blob/master/training/bing_bert/ds_sa_train_bert_bsz64k_seq128.sh#L18
超快稠密transformer核(Ultra-fast dense transformer kernels)
实现原理
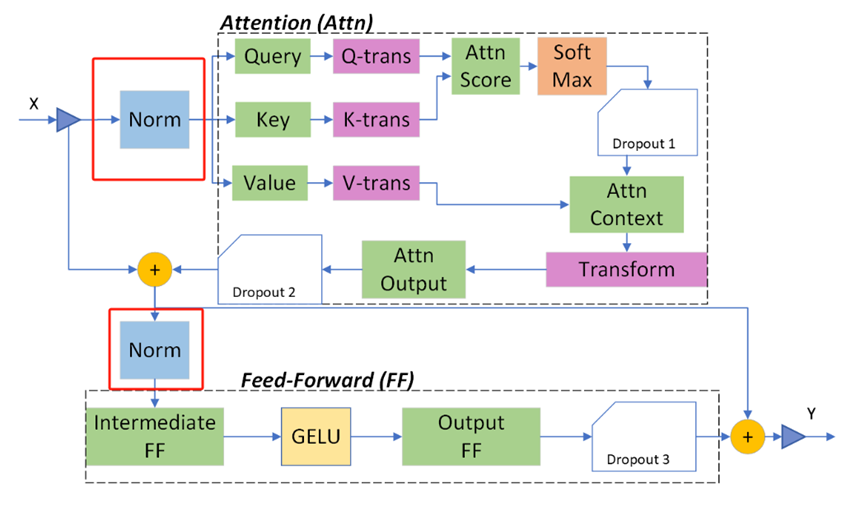
GPU有非常高的浮点数峰值吞吐量,但是默认的transformer实现远远达不到这个峰值。图6展示了Deepspeed实现的在两个子模块前做layer norm的transformer模块,同时也加入了2个优化:先进的融合内核和可逆算子.
1)融合内核减少数据移动
基于Transformer的网络触发了许多以生产者-消费者方式运行的CUDA内核调用,这增加了从全局内存传输数据和内核启动的开销。现有的编译器方法执行细粒度融合(例如,逐元素操作的融合),导致了错过了一些融合机会。相比之下,我们充分利用细粒度和粗粒度融合,并针对Transformer块进行优化。
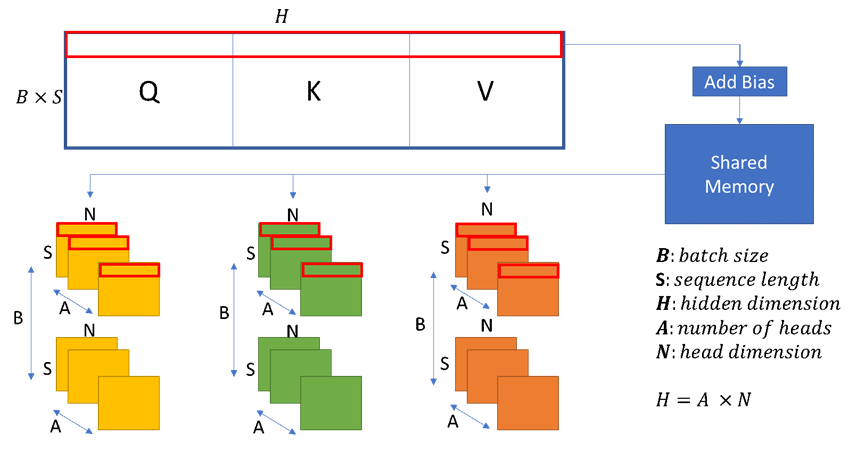
QKV和各种融合。我们将三个Query (Q)、Key (K)和Value (V)的权重矩阵合并,以调度更大的QKV GEMM(General Matrix Multiplication),以增加GPU共享内存和寄存器文件上的并行性,并提高数据本地性,如图7所示。接下来,我们将QKV输出矩阵的数据布局转换与偏置相加进行组合。然后,我们将大的QKV矩阵分割为三个转换后的矩阵,用于后面的自注意力计算。
正如图7所示,我们按连续的行读取QKV矩阵(由红色框显示),并将它们写入三个转换后的Q、K和V矩阵中。由于每个矩阵从不同的偏移开始,我们可能会对主存进行非连续的访问。因此,我们使用共享内存作为中间缓冲区,以便以一种方式重新排列数据,使得我们可以将数据放置在内存的连续部分。尽管在访问共享内存时产生了非连续的模式,但我们降低了对主存的非连续访问成本,以更好地利用内存带宽,最终导致端到端训练性能提高了3%到5%。将注意力输出的GEMM操作中的偏置相加与残差连接和丢弃操作相结合,这样可以在寄存器文件和共享内存中进行访问,这比昂贵的写回全局内存快几个数量级。
线程束级通信。为了减轻并行GPU核心之间的同步开销,并进一步提高融合内核的资源利用率,我们使用线程束级别(数据shuffle指令)而不是默认的线程束间通信。以层归一化LayerNorm和SoftMax内核为例,我们在一个线程束内执行每个reduction操作**。**通过这种方式,我们减轻了并行线程之间的同步,进一步提高了GPU资源的利用率。
随机性与确定性内核。深度学习训练通常对一定程度的随机性具有鲁棒性,在某些情况下,受控制的噪声(例如dropout)可以作为正则化器,提高泛化能力。在设计我们的Transformer内核时,我们采用了一定程度的随机性,通过允许内核中存在有限的数据竞争条件来提高吞吐量:我们利用隐式线程束同步编程实现了更高性能的线程束级协作操作。没有显式的线程束级同步作为非确定性噪声,不影响Transformer内核的整体收敛行为,同时提供了相当可观的吞吐量提升。
隐式线程束同步和显式线程束同步是GPU编程中两种不同的同步机制。
1.范围:隐式warp同步是在一个warp(通常包含32个线程)内部进行同步,而显式warp同步可以跨越不同的warp和线程块进行同步;
2.使用方式:隐式warp同步使用CUDA内置函数__syncwarp()来实现,只需要在代码中插入同步点即可。而显式warp同步需要使用__syncthreads()函数,在代码中显式地调用以确保线程块内的所有线程同步;
3.灵活性:显式warp同步更为灵活,可以在线程块内部的任意位置进行同步,而隐式warp同步只能在warp内部进行同步;
4.开销:由于隐式warp同步仅同步一个warp内的线程,因此开销相对较小。而显式warp同步需要同步整个线程块的所有线程,开销相对较大;
5适用场景:隐式warp同步适用于要在一个warp内部进行同步的场景。如并行归约(reduction)等,显式线程同步适用于需要在整个线程块内进行同步的场息,如共享内存的数据传输和计算等。
总的来说,隐式warp同步更为轻量级且适用于特定的同步需求,而显式warp同步更加灵活但开销较大,在编写GPU程序时,根据具体的同步需求选择合适的同步机制能够提高程序的性能和准确性。
此外,DeepSpeed还实现了一个具有显式线程束同步的非随机Transformer内核,以牺牲一定性能回归的代价获得确定性结果。用户可以根据使用场景轻松选择和切换两个版本:随机版本追求最终的训练性能目标,而确定性版本可以通过更好地促进实验和调试来节省开发时间。
在我们的实验中,我们对预训练的BERT使用随机内核,而对微调任务使用非随机内核,以实现完全可重现的结果。我们建议在涉及大量数据的训练任务(例如预训练)中使用随机内核,而在使用有限数据进行微调等情况下使用非随机版本以获得更一致的结果。
低成本的重新计算。在融合不同操作的内核时,我们观察到一些算子难以通过融合计算,但会产生昂贵的数据移动成本,例如添加偏置和dropout。对于这些操作,我们避免在前向传播中保存它们的结果,而是在反向传播期间重新计算它们,这比将结果写入和从主存中重新加载要快得多。
2) 可逆算子节省显存
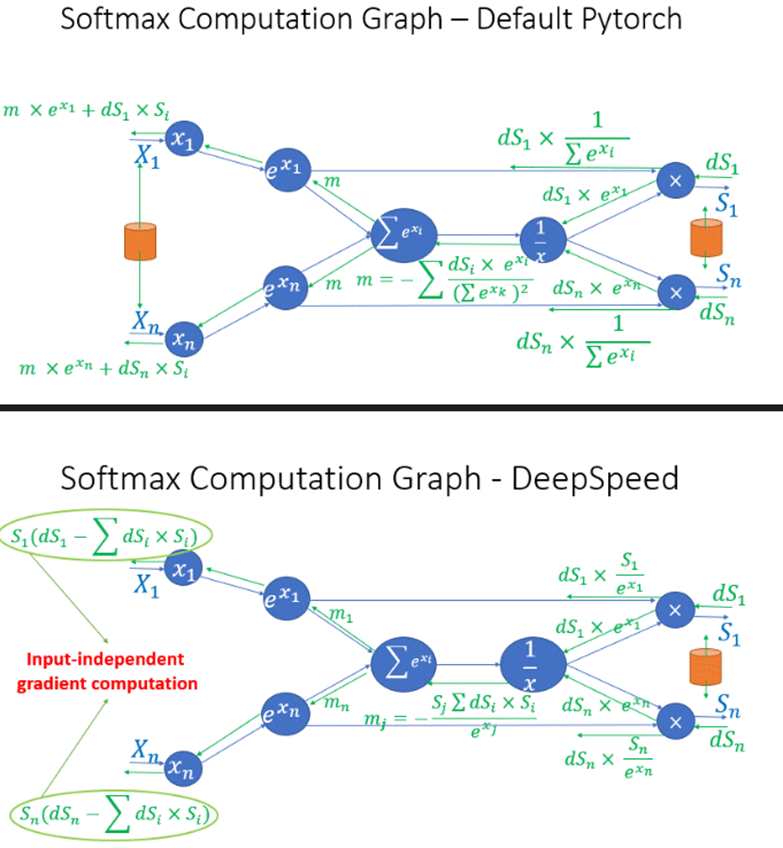
在Transformer模块中,我们还观察到几个操作符的中间激活会占用大量内存,例如SoftMax和Layer Norm。针对这些操作符,我们通过丢弃这些层的输入来减少激活内存的占用,这是因为它们是可逆函数(invertible functions),即其反向传播与输入无关,仅基于输出进行计算。图8展示了PyTorch中SoftMax的原始实现与DeepSpeed中可逆SoftMax实现的示例,橙色圆柱体为储存数据。通过这种优化,我们能够将操作符的激活内存减少一半,而这减少的内存允许我们使用更大的批次大小进行训练,从而再次提高GPU的效率。
性能表现
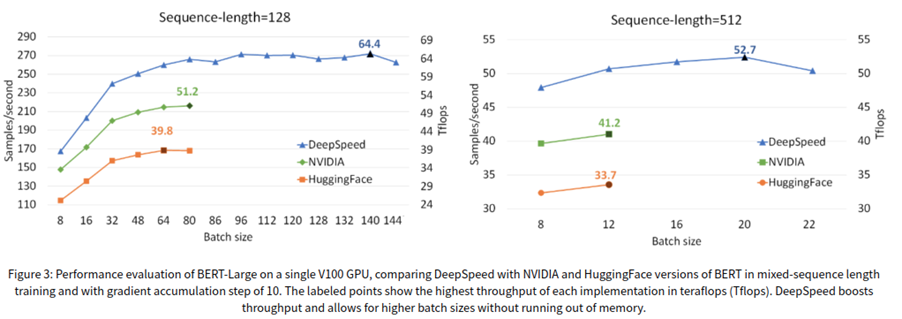
Deepspeed发布时重点宣传了transformer核,跟ZeRO-2并列,主要作用是通过核优化加速单卡性能,在V100上实现了64tflops的性能,比硬件本身的峰值性能高50%,训练BERT的时间从67分钟缩短到44分钟(V100x1024),如图9所示,transformer核不但实现了更快的速度,吞吐量比英伟达高28%,比HF高62%,并且支持的batch_size是1.8倍。
代码示例
以BingBertGlue训练代码为例,
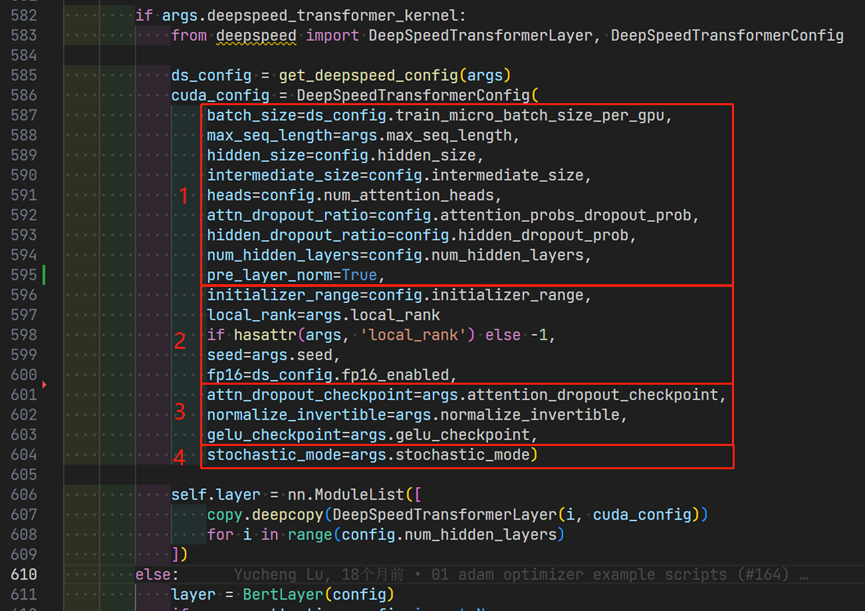
参数主要分为4个大类:
-
通用配置,用于不同类型的Transformer层
-
环境参数,指定系统设置
-
高性能优化flag,通过随机计算优化训练
- stochastic_mode:通过打开此flag,训练速度可以平均提高2%。请注意,该标志具有一定程度的不确定性,并且可能在不同运行中产生不同的结果。然而,我们发现通过启用该标志,不会影响BERT等预训练任务,并且可以获得高精度。另一方面,对于下游任务(如微调),我们建议关闭该标志,以便通过常规的内核执行能够复现相同的结果。
-
内存优化flag,以牺牲计算能力为代价节省内存
- attn_dropout_checkpoint:启用注意力dropout的检查点,以节省内存
- normalize_invertible:启用可逆LayerNorm执行(丢弃输入激活)
- gelu_checkpoint:启用Gelu激活输出的检查点,以节省内存
重点是3和4。
我们在Transformer内核中提供了几种技术,可以在层的不同部分节省内存。我们将它们作为可配置的设置暴露出来,可以在调用内核时启用。通过打开这些优化标志中的每一个,我们可以支持更大的批次大小。尽管我们通过使用其中一些技术来以性能为代价节省内存,但通过使用更大的批次大小,端到端训练效率会提高。
通过设置normalize_invertible标志,我们强制内核丢弃Transformer的归一化层的输入激活。我们之所以能够这样做,是因为内核包含一种优化,仅使用输出激活计算该层的参数和输入的梯度。
attn_dropout_checkpoint和gelu_checkpoint标志是指检查点方法,其中我们丢弃Transformer层的某些部分、注意力dropout和Gelu的输入,以节省重要的激活内存。根据我们的性能分析,重新生成这两个部分的成本微乎其微,最终从运行更大批次大小获得的性能收益可以弥补这一点。
通信压缩的优化器(1-bitAdam、0/1 Adam、1-bit LAMB)
大规模模型(如BERT和GPT-3)的可扩展训练需要在模型设计、架构和系统能力方面进行仔细优化。从系统角度来看,通信已经成为一个主要瓶颈,特别是在具有标准TCP互连的商品系统上,其网络带宽有限。通信压缩是一种重要的技术,可以减少这类系统上的训练时间。最有效的通信压缩方式之一是通过误差补偿压缩,即使在1位压缩下也能提供稳健的收敛速度。然而,最先进的误差补偿技术只适用于基本优化器,如随机梯度下降(SGD)和动量SGD,它们在梯度上是线性依赖的。它们无法与非线性梯度优化器(如Adam)一起使用,而Adam在许多任务中,包括训练类似BERT的模型时,提供了最先进的收敛效率和准确性。对于像Adam这样强大的优化器,梯度的非线性依赖(在方差项中)使得开发基于误差补偿的压缩技术变得具有挑战性,从而限制了最先进的通信压缩技术的实际价值。
实现原理
通信压缩的一种方式是1位压缩,可以表示为:
$$x \to \frac{|x|}{|\text{Sign}(x)|} \text{Sign}(x)$$
通过使用这种压缩方法,我们可以通过使用1位来表示每个数字,从而实现内存大小的32倍减小。但问题是,使用这种直接的方法会显著降低收敛速度,使得这种方法不适用。为了解决这个问题,最近的研究表明,通过使用误差补偿压缩,我们可以期望几乎相同的收敛速度与通信压缩。误差补偿的思想可以总结为:1)进行压缩,2)记忆压缩误差,然后3)在下一次迭代中将压缩误差添加回去。对SGD进行误差压缩会产生:
$$x_t = x_{t-1} - \gamma C(g_t + e_{t-1}) $$
$$e_t = g_t + e_{t-1} - C(g_t + e_{t-1})$$
其中C(⋅)是1位压缩运算符。这种误差补偿的好处是,历史压缩误差 $e_t$ 和 $e_{t-1}$ 最终会相互抵消: $x_t = x_{t-1} - \gamma (g_t + e_{t-1} - e_t)$,从而使SGD的误差补偿成立。
举例说明:如果在第一步将3.3压缩为1,相当于从梯度中减去了2.3,那么在第二步中就要先把2.3加到梯度中去,然后再进行1-bit压缩。通过不断地补偿上一步的通信压缩误差,实验证明使用基于压缩误差补偿的1-bit压缩方法可以达到和原来SGD相同的收敛速度。

这种策略已被证明对于梯度线性相关的优化算法(如SGD和动量SGD)是有效的。
但是Adam更新参数的方式为:
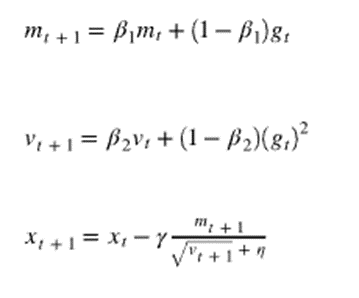
如上面公式所示,方差项 和梯度呈非线性关系,如果对Adam进行简单的误差补偿,Adam将会无法收敛。
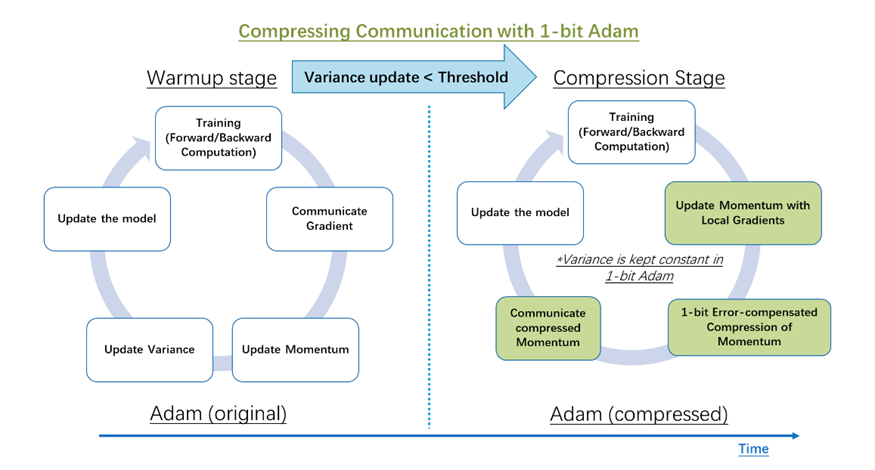
我们观察到非线性项方差(vt)的变化幅度在经过几个轮数的训练后显著减小,并且在之后设置 vt 常数不会改变收敛速度。建议的1-bit Adam 优化器如图11所示,由两部分组成:
预热阶段,本质上是普通Adam算法;
压缩阶段,检测到vt变化趋势稳定后,保持方差项不变,并将剩余的线性项,即动量,压缩为1位表示。(此时动量m相当于上面SGD证明里的梯度g)
性能表现
- 可以使用相同数量的训练样本实现和Adam一样的收敛速度
- 使用1-bit Adam训练的BERT评价指标比原版Adam高
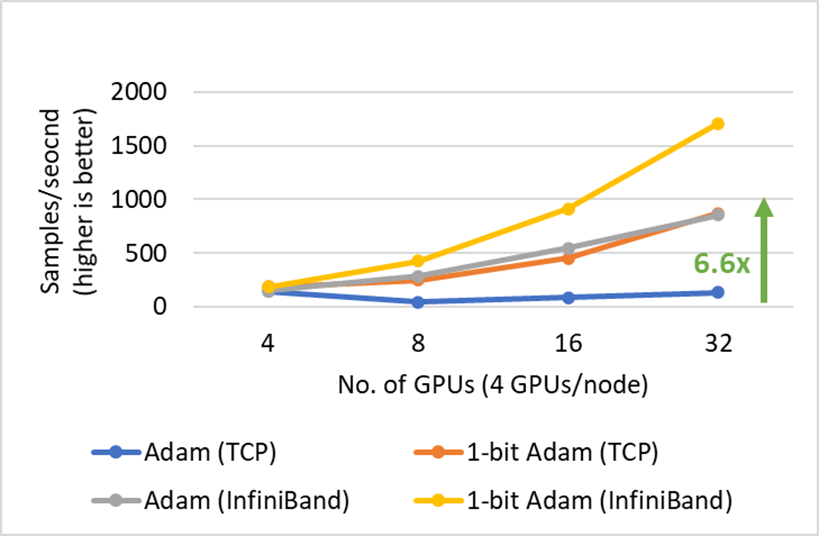
- 最多减少5倍的通信:1位Adam提供与Adam相同的收敛性,并在16位(FP16)训练的压缩阶段将通信量减少16倍。对于BERT预训练,这将导致整体通信减少5倍,因为我们观察到预热阶段仅占端到端训练时间的15%。
- BERT-Large整体训练速度快3.5x
- SQuAD上面微调速度快2.7x
代码示例
以BingBert训练代码为例,
在json配置文件中将优化器设置为OneBitAdam以启用1-bit Adam:
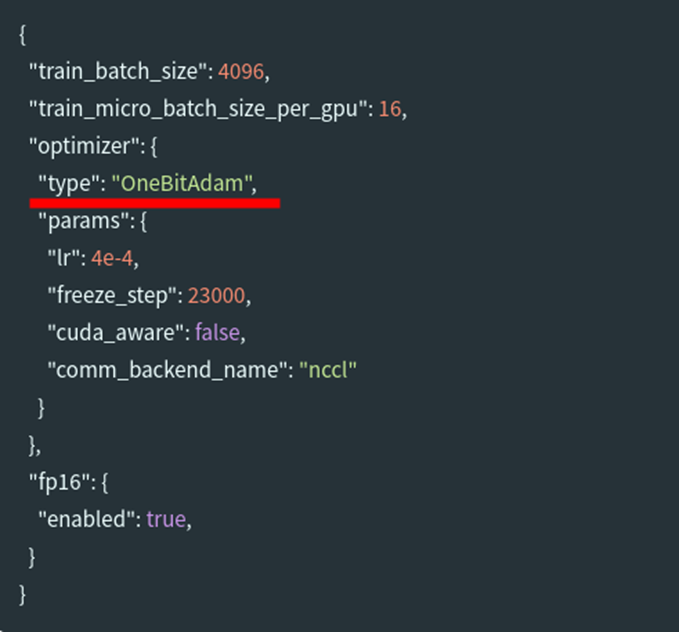
加入3个新的参数freeze_step, cuda_aware, 和 comm_backend_name
freeze_step是将1位压缩到通信之前的热身步骤的数量。为了确定热身步骤的数量,一种策略是为给定模型设置总训练步骤的15-25%,也可以通过系统地减少step来尝试提升性能。将来,我们计划引入一个可以自动搜索的阈值。
cuda_aware用于基于MPI的实现,以表明基础MPI库支持CUDA-AWARE-AWARE通信。此功能仅在具有Infiniband InterConnect和Cuda-Awance MPI库(如MVAPICH2-GDR或OPENMPI)的系统上支持此。将cuda_aware设置为false将允许对基于以太网的系统进行训练。但是,通信将在通信之前和之后使用发件人以及CPU和GPU缓冲区之间的接收器侧内存副本进行。
comm_backend_name用于指示要使用的后端实现。您可以通过将comm_backend_name设置为“ NCCL”和“ MPI”来在NCCL和基于MPI的实现之间进行选择。
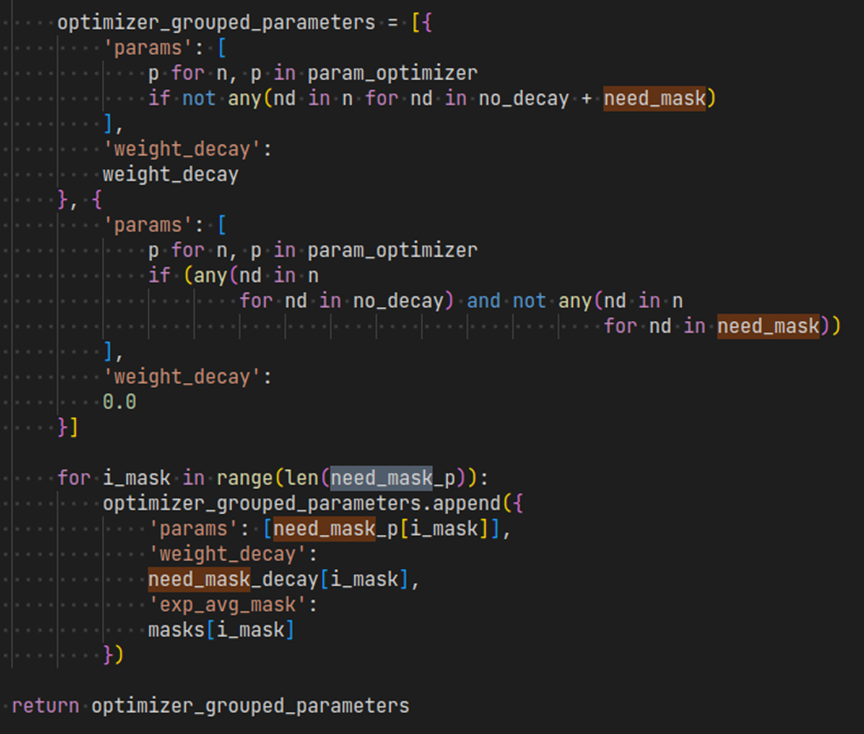
由于1位压缩不能代表精确的零,因此,如果参数在训练过程中具有恒定的零梯度,则压缩误差将继续在动量中积累。例如,对于BERT预训练seq长度128,Bert.embeddings.position_embeddings.Weight在其梯度和动量129至512中具有恒定的零,因为它只能学习到seq长度128,而模型则支持到seq长度512.因此,在1位Adam V2中,我们增加了动量mask的支持,以指定那些在其梯度中具有恒定零的参数。有关如何配置此动量mask,请参见以下示例脚本。
0/1 Adam
0/1 Adam优化器,它可以提高在通信受限集群上的模型训练速度,特别适用于通信稠密型的大型模型。例如,它可以在不影响端到端模型准确性的情况下,将BERT-large预训练的总体通信量减少多达26倍。与1-bit Adam优化器相比,0/1 Adam通过自适应方差状态冻结提供了一种更灵活的压缩通信方式。此外,它还允许计算节点在训练过程中使用一种称为1-bit同步的技术跳过通信轮次,而不会影响收敛速度。我们有一篇论文详细介绍了技术细节(https://arxiv.org/abs/2202.06009),包括算法、系统实现和评估结果。
使用方法与1-bit Adam类似:
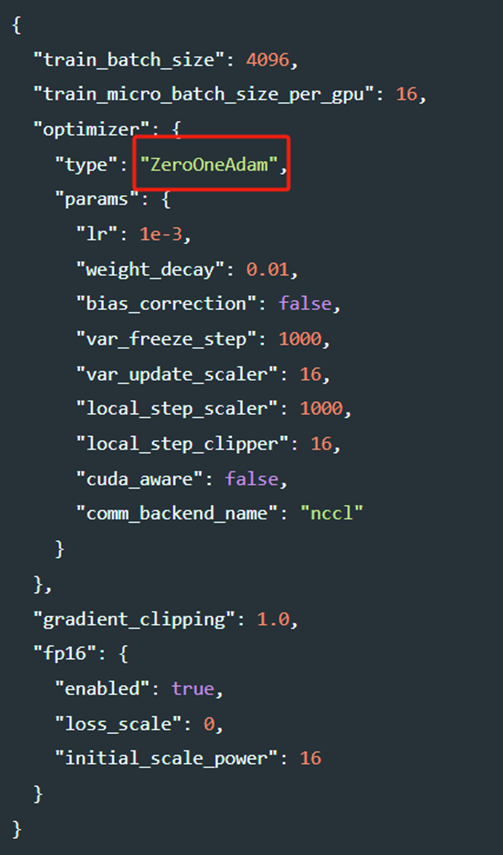
1-bit LAMB
1-bit LAMB优化器,它能够实现通信高效的大规模大批量训练,并具有LAMB的收敛速度。1-bit LAMB可以通过减少总体通信量高达4.6倍来提高在通信受限集群上的模型训练速度,特别适用于通信稠密型的大型模型。我们还有一篇论文(https://arxiv.org/abs/2104.06069)提供了技术细节,包括算法、系统实现和评估。
使用方法与1-bit Adam类似:
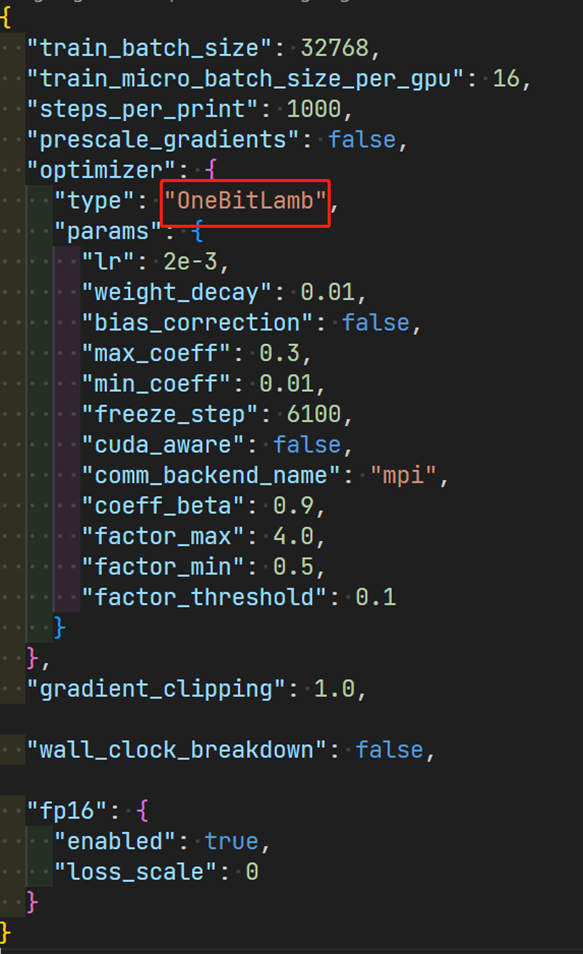
大语言模型低秩自适应(LoRA)
LoRA,英文全称Low-Rank Adaptation of Large Language Models,是微软研究员引入的一项新技术,主要用于处理大模型微调的问题,出自论文https://arxiv.org/abs/2106.09685。
自然语言处理的一个重要范式包括对一般领域数据的大规模预训练和对特定下游任务或领域的适应。当预训练更大的模型时,重新训练所有模型参数的完全微调变得不太可行。以GPT-3 175B为例,部署经过精细调整的模型的独立实例(每个实例都有175B参数)成本高昂。论文提出了低秩自适应(LoRA),它冻结了预训练的模型权重,并将可训练的秩分解矩阵注入Transformer架构的每一层,从而大大减少了下游任务的可训练参数数量。与用Adam微调的GPT-3175B相比,LoRA可以将可训练参数的数量减少10000倍,GPU内存需求减少3倍。LoRA在RoBERTa、DeBERTa、GPT-2和GPT-3上的模型质量方面表现相当或优于微调,尽管具有较少的可训练参数、较高的训练吞吐量,并且与适配器不同,没有额外的推理延迟。论文还对语言模型适应中的等级缺陷进行了实证研究,这揭示了LoRA的有效性。
实现原理
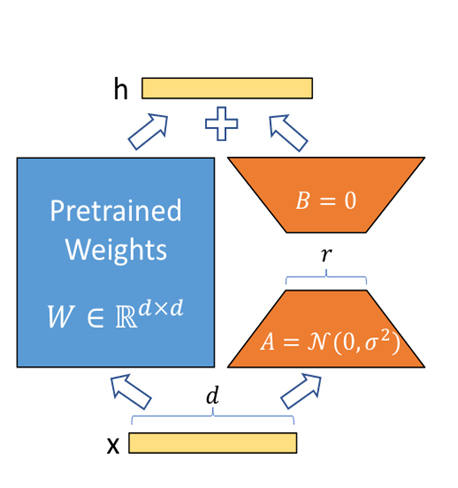
直观理解:W0为预训练权重,当有一个微调任务时,相当于将权重重新训练为,可以表示为两个低秩矩阵的乘积BA,其中,秩r是远小于预训练权重维度d的数,所以叫低秩。
那么我们固定预训练权重W0,而在预训练模型旁边增加一个旁路,只训练BA,就能实现微调,模型的输出变为了
$$ h = W_0 x + \Delta W x = W_0 x + B A x $$
LoRA详细过程
- 在原模型旁边增加一个旁路,通过低秩分解(先降维再升维)来模拟参数的更新量;
- 训练时,原模型固定,只训练降维矩阵A和升维矩阵B**;**
- 推理时,可将BA加到原参数上,不引入额外的推理延迟;
- 初始化,A采用高斯分布初始化,B初始化为全0,保证训练开始时旁路为0矩阵;
- 可插拔式的切换任务,当前任务W0+B1A1,将LoRA部分去掉后换成W0+B2A2,即可实现任务切换;
- 秩的选取:对于一般的任务,rank=1,2,4,8足矣,而对于一些领域差距比较大的任务可能需要更大的rank。
总的来说,LoRA就是冻结预先训练的模型权重,并将可训练的秩分解矩阵注入Transformer架构的每一层。目前对于大多数实验只在Wq和Wv使用LoRA,可训练参数的数量由秩r和原始权值的形状决定。
关键优势
- 预训练的模型可以共享,并用于为不同的任务构建许多小型LoRA模块。通过替换图13中的矩阵A和B,可以冻结共享模型参数并高效地切换任务,从而显著降低存储需求和任务切换开销。
- 当使用自适应优化器时,LoRA使训练更有效,并将计算硬件的门槛降低3倍,因为不需要计算梯度或维护大多数参数的优化器状态。相反,只优化注入的小得多的低秩矩阵。
- 简单的线性设计允许在部署时将可训练矩阵与冻结权重合并,与完全微调的模型相比,不会引入推理延迟。
典型应用
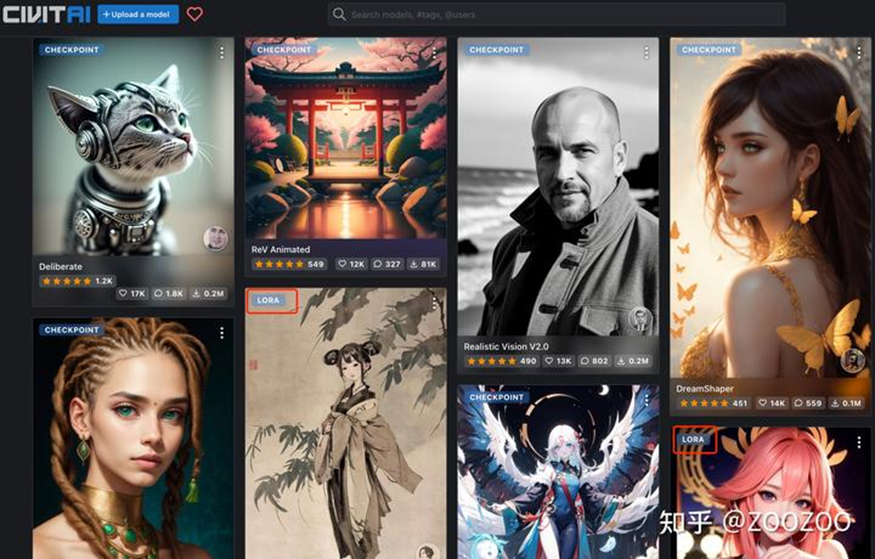
LoRA可以作为stable diffusion(SD)模型的一种插件,和hyper-network,controlNet一样,都是在不修改SD模型的前提下,利用少量数据训练出一种画风/IP/人物,实现定制化需求,所需的训练资源比训练SD模要小很多,非常适合社区使用者和个人开发者。
在著名的模型分享网站https://civitai.com/上,有大量的SD模型和LoRA模型,其中SD模型仅有2000个,剩下4万个基本都是LoRA等小模型。例如图14,水墨画和原神八重神子就是LoRA模型来实现特定的画风和人物IP。
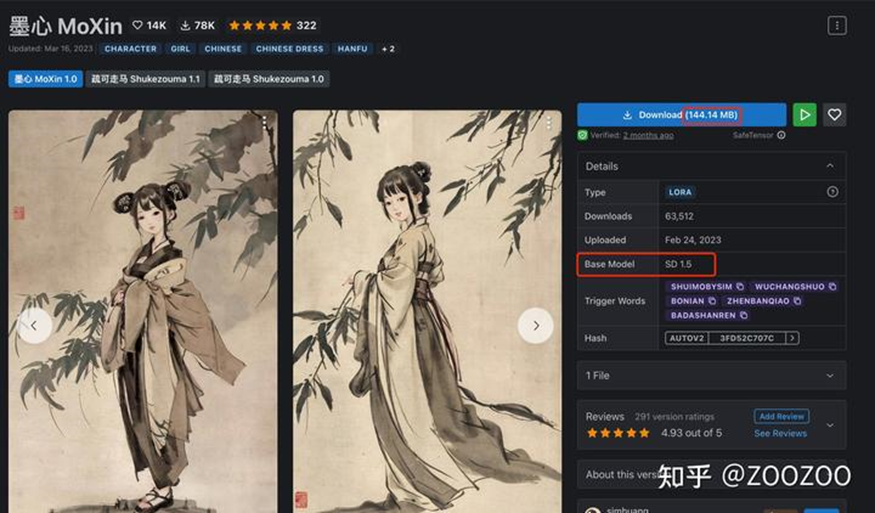
以下是一个LoRA模型,从图15可以看到,该模型只有144MB,相比SD模型至少2GB起步,LORA确实算得上是小模型,非常适合硬件资源受限的用户。LoRA是预训练模型的插件网络,所以必须配合预训练模型一起使用。图15中标注了Base Model: SD 1.5,意味着该模型是基于SD 1.5训练的,并且在使用时必须配合SD 1.5才能生成想要的效果。
代码示例
训练:
deepspeed启动命令行:

通过命令行或者配置文件,将LoRA配置传入训练脚本
如果在DeepSpeed初始化时传递了LoRA模型,那么DeepSpeed引擎将识别LoRA冻结参数。然而,流行的实现是初始化一个基本模型,然后再转换为LoRA模型。在这种情况下,用户需要在LoRA模型转换后显式调用DeepSpeed引擎。这只需要一行代码。下面显示了一个训练脚本的示例片段

转换方法:
使用Parameter-Efficient Fine-Tuning (PEFT),是huggingface开发的一个python工具,项目地址:https://github.com/huggingface/peft,可以很方便地实现将普通的大模型变成用于支持轻量级fine-tune的模型,使用非常便捷。
PEFT模型的使用非常方便,只需要按照原本的方式实例化模型,然后设置一下LoRA的config,调用一下get_peft_model方法,就获得了在原模型基础上的PEFT模型,对于LoRA策略来讲,就是在预训练参数矩阵W的基础上增加了矩阵分解的旁支。在下面的例子中,选择了attention中的q和v的部分做LoRA。
https://github.com/tloen/alpaca-lora/blob/main/finetune.py#L174-L184

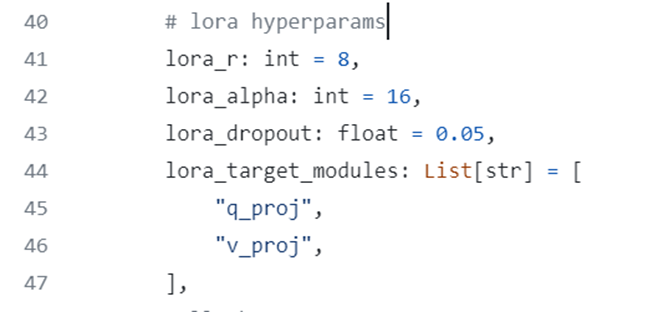
其中,LoRA参数直接写在训练代码里:
也可以像上面一样通过命令行传入
可以通过 model.print_trainable_parameters() 来打印lora训练的参数量,可以看到微调时只训练了0.16%的参数

模型训练完成后,可以调用PEFT重写的save_pretrained函数保存权重,该方法只会保存LoRA训练的部分,因此权重文件特别小
https://github.com/tloen/alpaca-lora/blob/main/finetune.py#L273-L275

推理:
https://github.com/tloen/alpaca-lora/blob/main/generate.py#L26-L52

model先加载预训练模型,然后再通过PEFT加载LoRA权重,执行后续推理。